DeepSeek's R1 lands on the open web and the frontier-AI cost curve flinches
A Chinese lab few in the West had been watching closely shipped a reasoning model competitive with OpenAI's o1 and a paper claiming it had been trained for under six million dollars. The market reaction was less about the model and more about what the model implied.
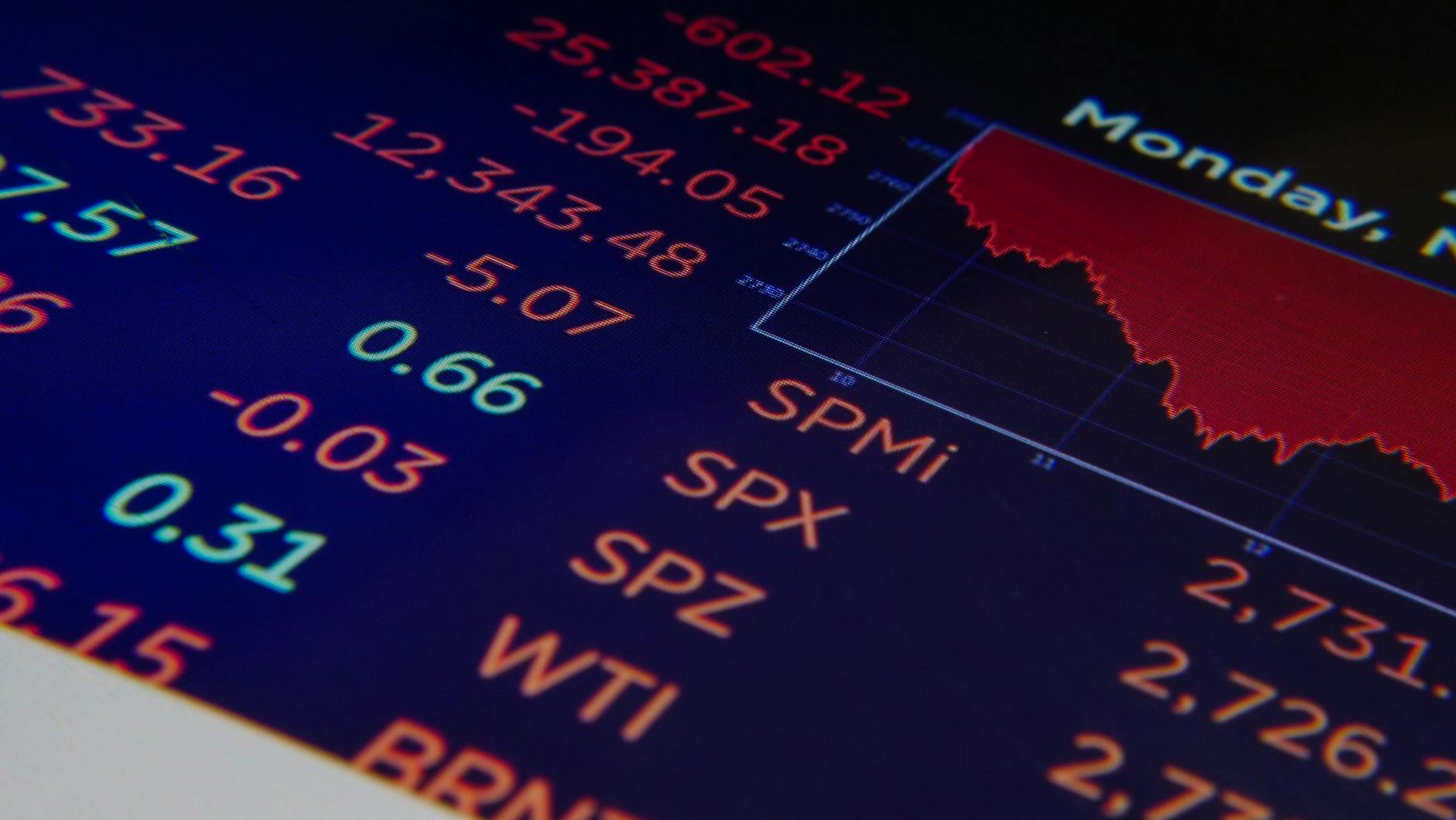
On 20 January 2025, DeepSeek, a research lab spun out of the Hangzhou-based hedge fund High-Flyer, published the weights and a technical report for R1, a reasoning model. The paper claimed the model had been trained with reinforcement learning on top of an open-source base model, on a cluster of approximately two thousand H800 GPUs, at a total compute cost the report put at under six million US dollars.
The capabilities, on the benchmarks reported, were comparable to OpenAI's o1, the reasoning model the American lab had launched at premium pricing the previous September. R1 ran on consumer hardware in quantised form, was released under an MIT licence, and was free to use through DeepSeek's chat product, which briefly topped the iOS App Store in the United States within a week of release.
A market reaction nobody expected
On Monday 27 January, the trading day after the release went viral, the Nasdaq Composite fell 3.1 per cent and Nvidia's market capitalisation dropped by approximately 600 billion US dollars in a single session, the largest single-day market-cap loss for any company in US stock-market history at that point. As reported by Bloomberg and the Financial Times, the move was driven by a sudden investor reassessment of the AI infrastructure capex thesis, which had assumed continually rising compute requirements.
It was not the model that moved the market. It was the report's bill of materials.
The numbers, scrutinised
The six-million-dollar figure was, in the days that followed, picked apart. As MIT Technology Review and The Information detailed in follow-up reporting, the figure covered only the final reinforcement-learning post-training run, not the cost of the base model, the data, the prior research that informed the recipe, or the depreciation on the GPU cluster, which DeepSeek's parent company had built up over years of quant trading. By comparable accounting, frontier models from US labs had not, in fact, cost the hundreds of millions of dollars sometimes claimed in the popular press, either.
The deeper point, made forcefully by Naomi Adekoya in her Substack the following week, was about pace. The gap between a publicly available frontier capability in San Francisco and a publicly available frontier capability with downloadable weights from Hangzhou had compressed from years to months. Whether or not the precise training-cost figure was right, the shape of the cost curve had changed visibly enough for markets to price it.



Discussion